在本文中,我们将详细介绍TrafficCV实现以及用于检测车辆和计算其速度的各种对象检测模型。在这里,我们讨论了一个基本的实现车辆速度检测算法使用哈尔目标检测器和目标相关跟踪器。
介绍
交通速度检测是一项大生意。世界各地的市政当局都用它来阻止超速者,并通过超速罚单赚取收入。但是,传统的速度探测器,通常是基于雷达或激光雷达,是非常昂贵的。
本系列文章将向您展示如何使用深入的学习构建一个相当精确的交通速度检测器,并在树莓Pi之类的边缘设备上运行它。
欢迎您从TrafficCV Git repository下载本系列的代码。我们假设你是Python,拥有人工智能和神经网络的基本知识。
在上一篇文章中,我们在Windows10上为TrafficCV程序设置了一个开发环境,我们将在Raspberry Pi上部署和测试代码。在本文中,我们将介绍TrafficCV的总体设计、该程序要解决的问题,以及使用对象检测器模型和对象相关跟踪器实现车辆检测器。
TrafficCV:是什么和能做什么
TrafficCV或任何OpenCV程序的基本功能是使用各种算法或神经网络模型逐帧分析视频,以分类对象、提取特征(如对象边界框)、计算点(如对象质心)、识别对象并通过视频帧跟踪它们。通常运行计时器来测量物体质心从一组像素坐标移动到另一组像素坐标所经过的时间。然后,程序可以使用这些信息,以及通过根据物理距离校准相机像素距离获得的常数来估计物体的速度
TrafficCV必须实时解决的基本问题是:
使用缩放、颜色空间或将在视频帧上运行的计算机视觉算法或模型所需的其他变换逐帧处理视频。
对车辆、行人等目标进行检测,得到具有一定置信阈值的所有车辆目标的边界框。
在整个视频中跟踪车辆–将当前帧中标识的对象与前一帧中标识的相同对象相关联。
测量视频中车辆覆盖的像素距离以及覆盖该距离所需的时间。
使用从摄像机属性和像素/物理距离校准获得的各种常数来估计车辆的速度。
以人类易于理解的方式显示计算出的信息。
首过探测器
让我们看看TrafficCV中的第一个通道(haarcascade_kraten)模型和检测器。这是最容易理解的车速检测器的实现,它将作为使用其他类型检测器的模板。首次通过检测器使用了由Kartike Bansal发布的OpenCV-Haar级联分类器模型和dlib库中的目标相关跟踪器。
分类器在CPU上运行,每fc帧检测车辆对象的边界框,其中fc是一个命令行检测器参数,默认值为10。所以每10帧我们检查是否有新的车辆物体出现。我们传递给对象相关跟踪器的其余帧计算每个现有车辆边界框的新位置。然后,速度估计器使用前一个和当前车辆边界框位置之间的距离(像素/米(ppm)和帧/秒(fps)常数)运行。这些约束条件必须通过物理测量和校准以及相机特性来获得。
然后,检测器使用OpenCV绘图和文本函数将框架上的边界框绘制为绿色,并将估计速度绘制为白色。估计的FPS以红色显示在顶部。
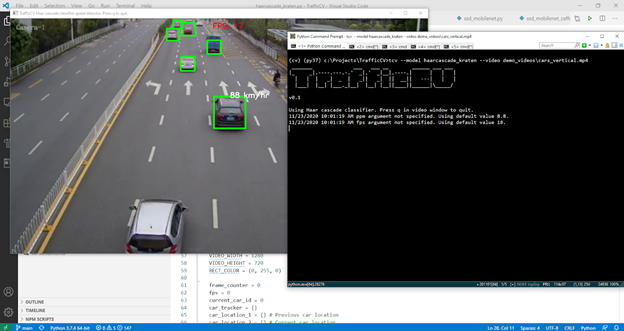
流量:Raspberry Pi 4上的Haar级联分类器
点击上面的链接,可以在YouTube上看到第一次尝试在pi4上运行的视频。要运行此模型,请下载TrafficCV模型文件和演示视频。解压TrafficCV文件夹中的档案,这样您就有了模型和演示视频子目录。在窗户上,你可以说
tcv --model haarcascade_kraten --video demo_videos\cars_vertical.mp4
./tcv MYHOST:0.0 --model haarcascade_kraten \
--video demo_videos/cars_vertical.mp4
./tcv $DISPLAY --model haarcascade_kraten \
--video demo_videos/cars_vertical.mp4
让我们看看haarcascade中的代码_克拉腾.py文件来查看上面的任务1-6是如何在Python中实现的。首先,我们使用预先训练的模型文件以及输入视频的视频源设置CascadeClassifier的实例,然后读取用户指定的参数:
classifier = cv2.CascadeClassifier(model_file)
video = cv2.VideoCapture(video_source)
ppm = 8.8
if 'ppm' in args:
ppm = args['ppm']
VIDEO_WIDTH = 1280
VIDEO_HEIGHT = 720
RECT_COLOR = (0, 255, 0)
frame_counter = 0
fps = 0
current_car_id = 0
car_tracker = {}
car_location_1 = {} # Previous car location
car_location_2 = {} # Current car location
speed = [None] * 1000
while True:
start_time = time.time()
_, image = video.read()
if image is None:
break
image = cv2.resize(image, (VIDEO_WIDTH, VIDEO_HEIGHT))
result = image.copy()
frame_counter += 1
...下一步是用当前帧更新dlib相关跟踪器:
for car_id in car_tracker.keys():
tracking_quality = car_tracker[car_id].update(image)
if tracking_quality < 7:
car_ids_to_delete.append(car_id)
for car_id in car_ids_to_delete:
debug(f'Removing car id {car_id} + from list of tracked cars.')
car_tracker.pop(car_id, None)
car_location_1.pop(car_id, None)
car_location_2.pop(car_id, None)
跟踪质量变量实际上是一个称为峰值旁瓣比的值,dlib对象跟踪器在更新被跟踪对象的位置时计算该值。如果该值小于7,则该对象可能已消失,或被另一个对象遮挡,因此我们将其从跟踪器中移除。
我们接下来检查frame\计数器变量是否是fc参数的倍数。如果是,则在当前帧上运行分类器:
我们使用OpenCV函数将输入视频帧的颜色空间转换为Haar分类器中最常用的颜色空间BGR灰度,然后调用detectMultiScale函数。此函数的参数指定分类器将检测到的对象的最小边界框大小等参数。在我们的例子中,这个设置为24*24像素。对于每个检测到的车辆对象,我们计算边界框的质心: if not (frame_counter % fc):
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
cars = classifier.detectMultiScale(gray, 1.1, 13, 18, (24, 24))
然后,我们在上一次分类器运行期间检测到的所有先前车辆对象中循环,现在正在跟踪,并计算这些对象的质心:
for (_x, _y, _w, _h) in cars:
x = int(_x)
y = int(_y)
w = int(_w)
h = int(_h)
x_bar = x + 0.5 * w
y_bar = y + 0.5 * h
我们比较了边界盒和质心的每个检测到的对象与那些现有的对象,我们的跟踪器预测的位置。如果被跟踪对象的位置与检测到的对象的位置重叠,我们假设该检测到的对象与现有被跟踪对象相同(请记住,我们已经移除了被跟踪器中其他对象遮挡的现有对象)。如果没有对象以上述方式重叠,我们就假设检测到一个新对象。然后,我们为这个新对象分配一个ID,并为它创建一个跟踪器:
matched_car_id = None
for car_id in car_tracker.keys():
tracked_position = car_tracker[car_id].get_position()
t_x = int(tracked_position.left())
t_y = int(tracked_position.top())
t_w = int(tracked_position.width())
t_h = int(tracked_position.height())
t_x_bar = t_x + 0.5 * t_w
t_y_bar = t_y + 0.5 * t_h
if ((t_x <= x_bar <= (t_x + t_w)) and
(t_y <= y_bar <= (t_y + t_h)) and
(x <= t_x_bar <= (x + w)) and
(y <= t_y_bar <= (y + h))):
matched_car_id = car_id
因此,我们在当前帧中得到了新车辆对象(使用Haar级联分类器)和现有对象(在我们的对象相关跟踪器中)的位置。我们可以使用OpenCV矩形函数在框架上为这些对象绘制绿色边框:
if matched_car_id is None:
debug (f'Creating new car tracker with id {current_car_id}.' )
tracker = dlib.correlation_tracker()
tracker.start_track(image, dlib.rectangle(x, y, x + w, y + h))
car_tracker[current_car_id] = tracker
car_location_1[current_car_id] = [x, y, w, h]
current_car_id += 1
for car_id in car_tracker.keys():
tracked_position = car_tracker[car_id].get_position()
t_x = int(tracked_position.left())
t_y = int(tracked_position.top())
t_w = int(tracked_position.width())
t_h = int(tracked_position.height())
cv2.rectangle(result, (t_x, t_y), (t_x + t_w, t_y + t_h), RECT_COLOR, 4)
我们还使用为每个对象计算的位置更新car_location_2变量:
car_location_1变量包含在上一帧中计算的车辆对象的位置。所以我们现在可以用这两个位置来计算每个物体的速度:
car_location_2[car_id] = [t_x, t_y, t_w, t_h]
对于一个新物体,我们只估计它通过某个区域时的速度。速度计算只执行一次,我们将这些值存储在速度变量中。我们只在物体移动足够快时才显示速度。for i in car_location_1.keys():
if frame_counter % 1 == 0:
[x1, y1, w1, h1] = car_location_1[i]
[x2, y2, w2, h2] = car_location_2[i]
car_location_1[i] = [x2, y2, w2, h2]
if [x1, y1, w1, h1] != [x2, y2, w2, h2]:
# Estimate speed for a car object as it passes through a ROI.
if (speed[i] is None) and y1 >= 275 and y1 <= 285:
speed[i] = estimate_speed(ppm, fps, [x1, y1, w1, h1], [x2, y2, w2, h2])
if speed[i] is not None and y1 >= 180:
cv2.putText(result, str(int(speed[i])) + "
km/hr", (int(x1 + w1/2), int(y1-5)),cv2.FONT_HERSHEY_SIMPLEX,
0.75, (255, 255, 255), 2)
最后一位代码在一个窗口中显示包含所有矩形和文本注释的框架,并等待用户在希望跳出循环并结束程序时按键:
最终结果是一个窗口重放视频帧,显示检测到的车辆对象的边界框和估计的速度。
cv2.imshow('TrafficCV Haar cascade classifier speed detector. Press q to quit.', result)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
CPU使用注意事项
当我们第一次在Windows中对一个演示视频运行这个程序时,我们可以看到基本检测器正在从视频窗口输出工作,FPS计数器大约为18。但是,CPU的使用率很高,而且随着跟踪的车辆越来越多,CPU的使用率也越来越高。在带有移动ARM处理器的Pi上,我们每秒只能管理几帧。即使这样,如果我们通过linuxhtop程序跟踪CPU的使用情况,我们也会发现它很高。
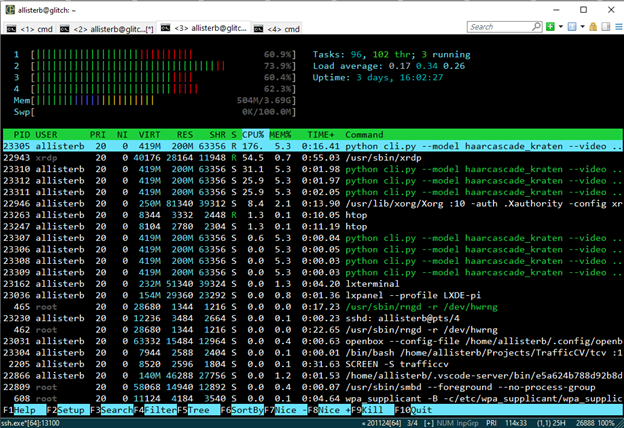
在RDP上运行TrafficCV的初始版本时,我们看到第一个CPU内核专用于xrdp服务器,而其他三个内核运行视频处理任务。然而,当我们使用在Windows上运行的远程X服务器时,CPU的使用率较低。它是单线程的,这表明在我们的视频处理线程上有阻塞的I/O操作占用了大量的时间。通过网络发送X帧所需的时间远远大于在OpenCV中处理视频帧所需的时间。
如果我们增加fc参数(增加分类器运行的间隔),我们可以增加FPS,因为相关跟踪器比分类器占用的CPU更少。但是有了一个基本的框架程序,我们现在可以使用TensorFlow探索更高级的速度检测模型。
下一步
在下一篇文章中,我们将重点开发一个计算机视觉框架,它可以在实时和录制的车辆交通视频上运行各种机器学习和神经网络模型(如SSD-MobileNet)。敬请期待!
