在本文中,我们将讨论如何使用扩充的数据集来训练DNN分类器。
在这里,我们将提出一个DNN模型来检测图像上的驼鹿。然后,我们将提供Python代码来生成用于使用Caffe训练DNN的输入数据。然后我们解释如何启动Caffe。最后,我们展示了训练日志并解释了结果。
不守规矩的野生动物对企业和房主来说都是一种痛苦。像鹿、驼鹿甚至猫这样的动物都会对花园、庄稼和财产造成损害。
在本系列文章中,我们将演示如何在树莓皮上实时(或接近实时)检测有害生物(如驼鹿),然后采取措施消除有害生物。因为我们不想造成任何伤害,所以我们将集中精力通过大声喧哗来吓跑害虫。
欢迎您下载该项目的源代码。我们假设您熟悉Python,并且对神经网络的工作方式有基本的了解。
在上一篇文章中,我们组装了一个用于moose检测的数据集,其中包含带有moose类和background类对象的图像。在本文中,我们将开发一个分类器DNN模型并在我们的数据集上进行训练。我们将使用Caffe创建和训练DNN。请在您的PC上安装此框架,以便后续操作。
开发一个DNN
DNN开发从创建模型结构开始。因为我们将在树莓P上使用我们的神经网络,所以模型应该是轻量级的,这样它就可以以适当的速度运行。
从头开始设计一个优化的DNN模型是一个相当复杂的任务,我们将不在这里详细描述。我们建议使用以下网络架构:
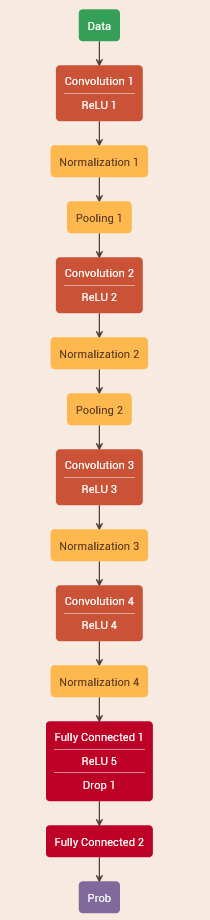
这是一个Caffe-DNN模型的可视化与一个免费的在线编辑器。它可能不是绝对最好的模式,但它绝对是足够好的,为我们的目的。
这源于AlexNet体系结构,它是第一个(也是最简单的)成功应用于图像分类的网络。我们对原始的体系结构进行了裁剪和优化,以便对少量的对象类别进行分类。得到的模型有四个64-128-128-64核的卷积层(卷积滤波器)。
还有两个池层用于将输入图片的尺寸减小到128×128像素。中间完全连接(FC)层有256个神经元,最后一个FC层有两个神经元(每个要分类的对象类别一个:背景和驼鹿)。
我们需要的另一个组件是训练模型,它是一个经过修改的分类模型,可以替换输入和输出层。
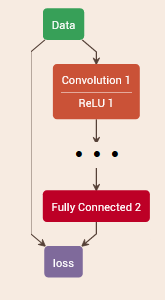
训练模型的输入层必须指定用于训练和测试的标记数据的来源。输出层必须指定损失函数,以使训练期间的输出最小化。
为了提供标记数据的源,我们创建文本文件,其中包含指向所有带有标签(图像的对象类别的标识符)的示例图像的路径。让我们将示例图像组织到以下文件夹中:
PI_PEST
如您所见,我们有两个主要的文件夹,Learning和Testing,分别用于培训和测试。0子文件夹用于背景示例,1子文件夹用于moose示例。
首先,将每个类的500个示例图像移动到测试目录,并将所有剩余图像移动到学习目录。现在让我们编写一些Python代码来生成源文件:
import os
import numpy as np
import cv2
class TrainFiler:
def get_labels(self, folder):
subfolders = os.scandir(folder)
labels = []
for classfolder in subfolders:
class_name = os.path.basename(classfolder)
files = FileUtils.get_files(classfolder)
for (i, fname) in enumerate(files):
label = fname + " " + class_name
labels.append(label)
return labels
def save_labels(self, labels, filename):
with open(filename, 'w') as f:
for label in labels:
f.write('%s\n' % label)
def gen_train_files(self, learn_folder, test_folder, learn_file, test_file):
labels = self.get_labels(learn_folder)
self.save_labels(labels, learn_file)
labels = self.get_labels(test_folder)
self.save_labels(labels, test_file)
learn_folder = r"C:\PI_PEST\Learning"
test_folder = r"C:\PI_PEST\Testing"
learn_file = r"C:\PI_PEST\classeslearn.txt"
test_file = r"C:\PI_PEST\classestest.txt"
filer = TrainFiler()
filer.gen_train_files(learn_folder, test_folder, learn_file, test_file)
…
C:\PI_PEST\Learning\0\vlcsnap-2020-10-26-16h13m39s332(x253,y219,w342,h342)fliprotate15.png 0
C:\PI_PEST\Learning\0\vlcsnap-2020-10-26-16h13m39s332(x253,y219,w342,h342)fliprotate_15.png 0
C:\PI_PEST\Learning\1\vlcsnap-2020-10-21-13h46m55s365(x106,y28,w633,h633).png 1
C:\PI_PEST\Learning\1\vlcsnap-2020-10-21-13h46m55s365(x106,y28,w633,h633)flip.png 1
…
…
C:\PI_PEST\Testing\0\vlcsnap-2020-10-26-16h16m22s719(x39,y36,w300,h300)smooth5rotate15.png 0
C:\PI_PEST\Testing\0\vlcsnap-2020-10-26-16h16m22s719(x39,y36,w300,h300)smooth5rotate_15.png 0
C:\PI_PEST\Testing\1\vlcsnap-2020-10-26-16h08m31s421(x276,y0,w566,h566)flipsharpen5.png 1
C:\PI_PEST\Testing\1\vlcsnap-2020-10-26-16h08m31s421(x276,y0,w566,h566)flipsharpen5rotate15.png 1
…
net: "classes_learn_test.prototxt"
test_iter: 1000
max_iter: 100000
base_lr: 0.001
solver_mode: CPU
要启动Caffe进行模型训练,我们需要将以下数据文件复制到Caffe可执行文件夹:classes\u learn_测试.prototxt(培训文件),classeslearn.txt文件以及classestest.txt文件(生成的培训和测试数据文件)和类_解算器.prototxt(解算器规范文件)。
使用以下命令启动培训过程:
caffe.exe train -solver=classes_solver.prototxt
在打开的控制台窗口中,您可以看到培训过程的进度:
I1028 09:10:24.546773 32860 solver.cpp:330] Iteration 3000, Testing net (#0)
I1028 09:13:12.228042 32860 solver.cpp:397] Test net output #0: accuracy = 0.95
I1028 09:13:12.229039 32860 solver.cpp:397] Test net output #1: loss = 0.209061 (* 1 = 0.209061 loss)
I1028 09:13:12.605070 32860 solver.cpp:218] Iteration 3000 (1.83848 iter/s, 543.929s/1000 iters), loss = 0.0429298
I1028 09:13:12.605070 32860 solver.cpp:237] Train net output #0: loss = 0.00469132 (* 1 = 0.00469132 loss)
I1028 09:13:12.608062 32860 sgd_solver.cpp:105] Iteration 3000, lr = 0.000800107
I1028 09:19:11.598755 32860 solver.cpp:447] Snapshotting to binary proto file classes_iter_4000.caffemodel
I1028 09:19:11.641045 32860 sgd_solver.cpp:273] Snapshotting solver state to binary proto file classes_iter_4000.solverstate
I1028 09:19:11.661990 32860 solver.cpp:330] Iteration 4000, Testing net (#0)
I1028 09:21:51.567586 32860 solver.cpp:397] Test net output #0: accuracy = 0.971
I1028 09:21:51.568584 32860 solver.cpp:397] Test net output #1: loss = 0.0755974 (* 1 = 0.0755974 loss)
I1028 09:21:51.942620 32860 solver.cpp:218] Iteration 4000 (1.92553 iter/s, 519.337s/1000 iters), loss = 0.0283988
I1028 09:21:51.942620 32860 solver.cpp:237] Train net output #0: loss = 0.0119124 (* 1 = 0.0119124 loss)
I1028 09:21:51.942620 32860 sgd_solver.cpp:105] Iteration 4000, lr = 0.000751262
I1028 09:29:05.931291 32860 solver.cpp:447] Snapshotting to binary proto file classes_iter_5000.caffemodel
I1028 09:29:06.011082 32860 sgd_solver.cpp:273] Snapshotting solver state to binary proto file classes_iter_5000.solverstate
I1028 09:29:06.042008 32860 solver.cpp:330] Iteration 5000, Testing net (#0)
I1028 09:32:13.374222 32860 solver.cpp:397] Test net output #0: accuracy = 0.877
I1028 09:32:13.374222 32860 solver.cpp:397] Test net output #1: loss = 0.861016 (* 1 = 0.861016 loss)
I1028 09:32:13.743319 32860 solver.cpp:218] Iteration 5000 (1.60823 iter/s, 621.8s/1000 iters), loss = 0.000519958
I1028 09:32:13.743319 32860 solver.cpp:237] Train net output #0: loss = 0.000306881 (* 1 = 0.000306881 loss)
I1028 09:32:13.745313 32860 sgd_solver.cpp:105] Iteration 5000, lr = 0.000708472我们应该监测的是准确度。在第4000次迭代时,它增加到97.1%,然后开始减少。这可能是由于训练模型的过度拟合。所以我们应该停止这个过程,从第4000次迭代中获取模型文件。
下一步
在下一篇文章中,我们将向您展示如何开发一个简单的运动检测器,并将其与经过训练的DNN模型相结合来检测视频中的驼鹿。
