数据集每天都在变大,GPU也在变快。这意味着有更多的数据集供深度学习研究人员和工程师训练和验证他们的模型。
1、许多用于静态图像识别研究的数据集正变得可用,包括OpenImages和place等1000万张或更多的图像。
2、数百万个YouTube视频(YouTube 8M)以720p的速度消耗约300 TB,用于对象识别、视频分析和动作识别的研究。
3、烟草语料库由大约2000万个高清扫描页面组成,可用于OCR和文本分析研究。
尽管目前最常见的大数据集涉及图像和视频,但大数据集出现在许多其他领域,并涉及许多其他类型的数据:网页、金融交易、网络跟踪、大脑扫描等。
然而,处理大量数据集带来了许多挑战:
1、数据集大小:数据集通常超过节点本地磁盘存储的容量,需要分布式存储系统和高效的网络访问。
2、文件数量:数据集通常由数十亿个具有统一随机访问模式的文件组成,这通常会淹没本地和网络文件系统。
3、洗牌和扩充:训练数据需要在训练前进行洗牌和扩充。
4、可伸缩性:用户通常希望在小型数据集上开发和测试,然后快速扩展到大型数据集。
传统的本地和网络文件系统,甚至对象存储服务器,都不是为这类应用程序设计的。PyTorch的WebDataset I/O库以及可选的AIStore服务器和Tensorcom RDMA库为所有这些问题提供了一个高效、简单且基于标准的解决方案。该库非常简单,适合日常使用,基于成熟的开放源码标准,并且易于从现有的基于文件的数据集迁移。
使用WebDataset很简单,只需很少的努力,它可以让您将相同的代码从运行本地实验扩展到在集群或云中使用数百个GPU,并具有线性可伸缩的性能。即使在小问题和桌面上,它也可以将I/O速度提高10倍,并简化数据管理和大型数据集的处理。这篇博文的其余部分将告诉您如何开始使用WebDataset及其工作原理。
WEBDATASET库
WebDataset库为上述挑战提供了一个简单的解决方案。目前,它作为一个单独的库提供(github.com/tmbdev/webdataset),但它正在被纳入PyTorch的轨道上(见RFC 38419)。WebDataset实现很小(大约1500 LOC),没有外部依赖关系。
WebDataset没有发明新的格式,而是将大型数据集表示为由原始数据文件组成的POSIX tar归档文件的集合。WebDataset库可以直接使用这样的tar档案进行培训,而不需要解包或本地存储。
WebDataset可以在数百个GPU上完美地从小型本地数据集扩展到PB级数据集和培训,并允许数据存储在本地磁盘、web服务器或专用文件服务器上。对于基于容器的培训,WebDataset不再需要卷插件或节点本地存储。作为一个额外的好处,数据集不需要在培训前解包,简化了研究数据的分发和使用。
WebDataset实现了PyTorch的IterableDataset接口,可以像现有的基于DataLoader的代码一样使用。由于数据作为文件存储在归档文件中,因此现有的加载和数据扩充代码通常只需要很少的修改。
WebDataset库是一个完整的解决方案,可以在PyTorch中处理大型数据集和分布式培训(还可以通过pythonapi与TensorFlow、Keras和DALI一起使用)。由于POSIX tar存档是一种标准的、广泛支持的格式,因此很容易编写其他工具来处理这种格式的数据集。E、 例如,tarp命令是用Go编写的,可以洗牌和处理训练数据集。
好处
对于非常大的数据集,使用分片的、顺序可读的格式是必不可少的。此外,它在许多其他环境中也有好处。WebDataset提供了一个解决方案,它可以很好地从桌面机器上的小问题扩展到集群或云中的非常大的深度学习问题。下表总结了在不同环境中的一些好处。
|
环境 |
WebDataset的好处 |
|
带AIStore的本地群集 |
AIStore可以作为K8s容器轻松部署,并提供线性可扩展性和接近100%的网络和I/O带宽利用率。适合花瓣级深度学习。 |
|
云计算 |
WebDataset深度学习作业可以直接针对存储在云存储桶中的数据集进行培训;不需要卷插件。本地作业和云作业的工作方式相同。适合花瓣级学习。 |
|
具有现有分布式FS或对象存储的本地群集 |
WebDataset的大型顺序读取提高了现有分布式存储的性能,并消除了对专用卷插件的需求。 |
|
教育环境 |
webdataset可以存储在现有的web服务器和web缓存中,学生可以通过URL直接访问 |
|
本地驱动器工作站训练 |
当数据仍在下载时,乔布斯可以开始培训。培训时不需要打开数据包。与基于随机访问文件的数据集相比,硬盘的I/O性能提高了10倍。 |
|
所有环境 |
数据集以存档格式表示,并包含诸如文件类型之类的元数据。数据以本机格式(JPEG、MP4等)压缩。数据管理、ETL风格的作业、数据转换和I/O都被简化并易于并行化。 |
高性能
对于本地集群上的高性能计算,配套的开源AIStore服务器提供完整的磁盘到GPU的I/O带宽,仅受硬件限制。Bigdata 2019论文包含详细的基准和性能度量。除了基准测试之外,NVIDIA和微软的研究项目还将WebDataset用于petascale数据集和数十亿个训练样本。
下面是AIStore与WebDataset客户端的基准测试,使用12个服务器节点,每个节点有10个旋转驱动器。
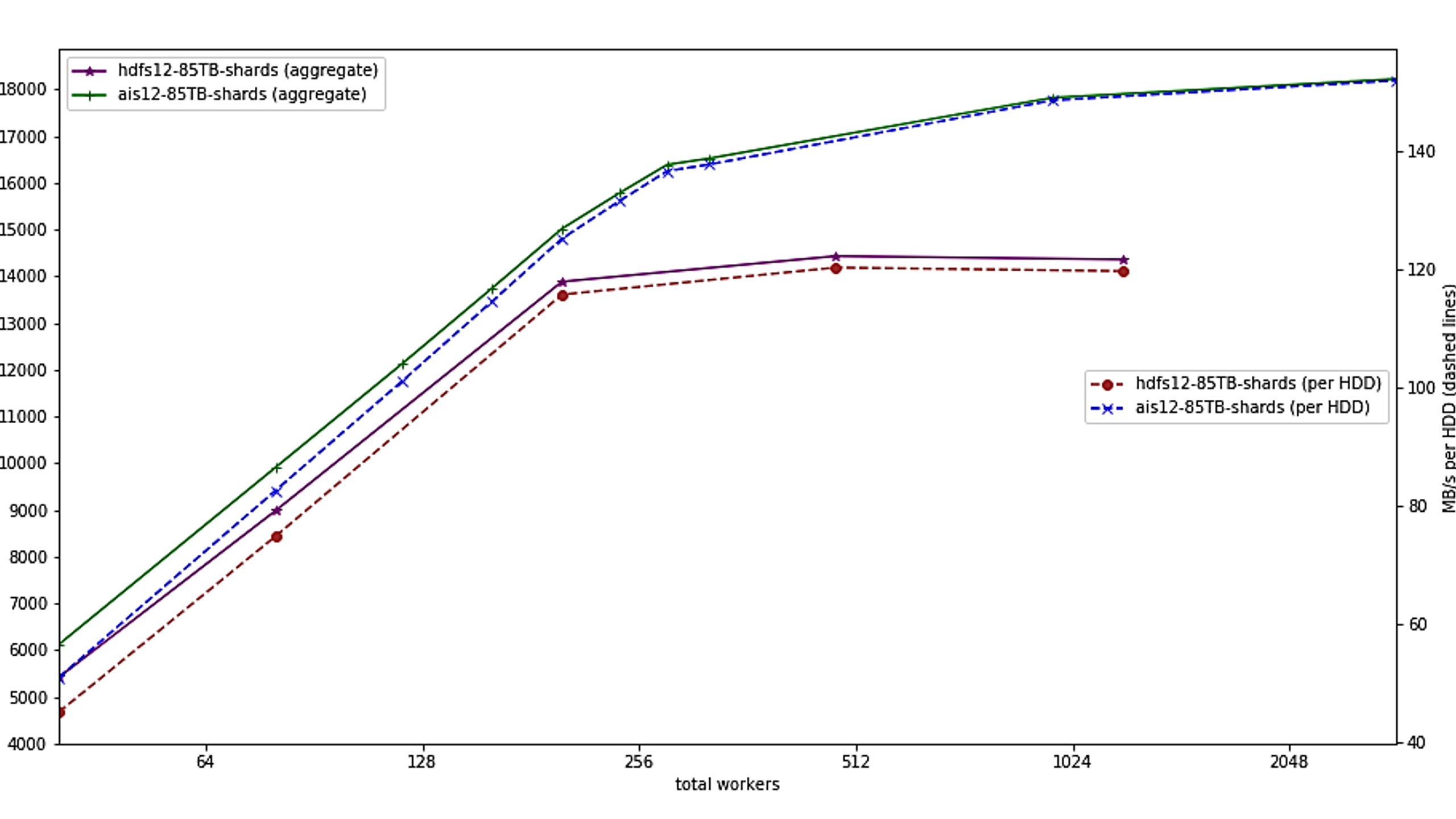
左轴显示集群的聚合带宽,右刻度显示测量的每个驱动器I/O带宽。WebDataset和AIStore线性扩展到大约300个客户端,此时它们越来越受到来自旋转驱动器的最大I/O带宽的限制(每个驱动器大约150 MB/s)。为了进行比较,显示了HDFS。HDFS使用了与AIStore/WebDataset类似的方法,并且还可以线性扩展到大约192个客户机;此时,它达到了每个驱动器大约120mbytes/s的性能限制,并且在使用超过1024个客户机时失败。与HDFS不同,基于WebDataset的代码只使用标准url和HTTP访问数据,并与本地文件、存储在web服务器上的文件以及AIStore完全相同。相比之下,NFS在类似的实验中,每个驱动器的速度大约为10-20mbytes/s。
在TAR存档中存储数据集
WebDataset使用的格式是标准POSIX tar存档,与备份和数据分发使用的存档相同。为了使用该格式存储培训样本以进行深入学习,我们采用了一些简单的命名约定:
数据集是POSIX tar存档
每个训练样本都由具有相同基名称的相邻文件组成
碎片是连续编号的
例如,ImageNet存储在1282个单独的100兆字节分片中,名称为pythonimagenet-train-000000.tar到ImageNet-train-001281.tar,第一个分片的内容是:
-r--r--r-- bigdata/bigdata 3 2020-05-08 21:23 n03991062_24866.cls
-r--r--r-- bigdata/bigdata 108611 2020-05-08 21:23 n03991062_24866.jpg
-r--r--r-- bigdata/bigdata 3 2020-05-08 21:23 n07749582_9506.cls
-r--r--r-- bigdata/bigdata 129044 2020-05-08 21:23 n07749582_9506.jpg
-r--r--r-- bigdata/bigdata 3 2020-05-08 21:23 n03425413_23604.cls
-r--r--r-- bigdata/bigdata 106255 2020-05-08 21:23 n03425413_23604.jpg
-r--r--r-- bigdata/bigdata 3 2020-05-08 21:23 n02795169_27274.cls
训练期间的洗牌对于许多深度学习应用程序非常重要,WebDataset在shard级别和sample级别执行洗牌。使用用户提供的shard\u选择函数在shard级别执行跨多个worker的数据拆分,该函数默认为基于get\u worker\u info进行拆分的函数。(WebDataset可以与tensorcom库结合,以减轻解压/数据扩充的负担,并提供RDMA和直接到GPU的加载;见下文。)
代码例子
下面是一些代码片段,演示了如何在典型的PyTorch深度学习应用程序中使用WebDataset(您可以在http://github.com/tmbdev/pytorch-imagenet-wds。
import webdataset as wds
import ...
sharedurl = "/imagenet/imagenet-train-{000000..001281}.tar"
normalize = transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
preproc = transforms.Compose([
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
normalize,
])
dataset = (
wds.Dataset(sharedurl)
.shuffle(1000)
.decode("pil")
.rename(image="jpg;png", data="json")
.map_dict(image=preproc)
.to_tuple("image", "data")
)
loader = torch.utils.data.DataLoader(dataset, batch_size=64, num_workers=8)
for inputs, targets in loader:
...
此代码与PyTorch Imagenet示例中基于文件的I/O管道几乎相同:它创建预处理/扩充管道,使用该管道和数据源位置实例化数据集,然后从数据集构造DataLoader实例。
WebDataset使用fluent API进行内部构建处理管道的配置。在本例中,没有添加任何处理阶段,WebDataset与PyTorch DataLoader类一起使用,PyTorch DataLoader类跨多个线程复制数据集实例,并执行并行I/O和并行数据扩充。
WebDataset实例本身只是作为字典遍历每个训练样本:
# load from a web server using a separate client process
sharedurl = "pipe:curl -s http://server/imagenet/imagenet-train-{000000..001281}.tar"
dataset = wds.Dataset(sharedurl)
for sample in dataset:
# sample["jpg"] contains the raw image data
# sample["cls"] contains the class
...
相关软件
1、AIStore是一个开放源代码对象存储,能够提供全带宽磁盘到GPU的数据传输(这意味着,如果您有1000个读取速度为200 MB/s的旋转驱动器,AIStore实际上可以向GPU提供200 GB/s的总带宽)。AIStore作为客户机与WebDataset完全兼容,而且还了解WebDataset格式,允许它直接在存储系统中执行洗牌、排序、ETL和一些map reduce操作。AIStore可以看作是分布式对象存储、网络文件系统、分布式数据库和GPU加速的map-reduce实现的混合体。
2、tarp是一个小型的命令行程序,用于分割、合并、洗牌和处理tar存档和WebDataset数据集。
3、tensorcom是一个支持分布式数据扩充和RDMA到GPU的库。
4、pytorch imagenet wds包含一个基于pytorch imagenet示例的如何将WebDataset与imagenet一起使用的示例。
带基准的Bigdata 2019论文
