论文"Attention Is All You Need"(在这个网址能下载到该论文https://proceedings.neurips.cc/paper_files/paper/2017/file/3f5ee243547dee91fbd053c1c4a845aa-Paper.pdf),
摘要
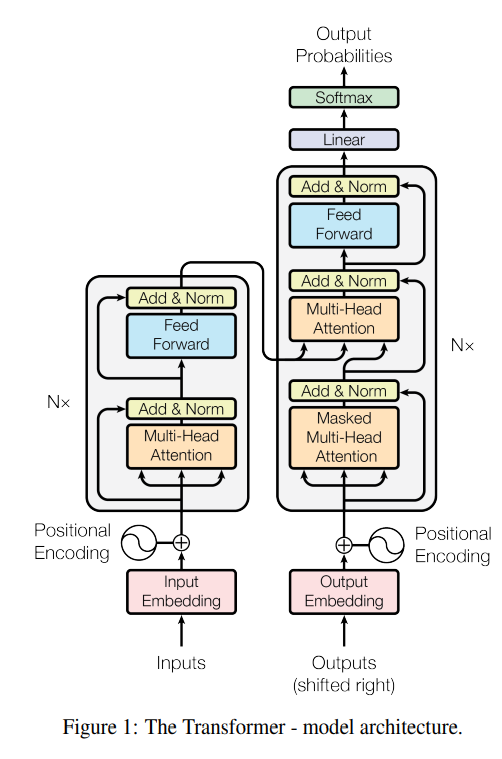
显性序列转导模型基于复杂的循环或卷积神经网络,包括编码器和解码器。最好的执行模型还通过注意力连接编码器和解码器机制。我们提出了一种新的简单网络架构Transformer,仅基于注意力机制,完全无需循环和卷积。在两个机器翻译任务上的实验表明,这些模型质量更高,同时更具并行性,要求更高训练时间更少。我们的模型在WMT 2014英语到德语的翻译任务中达到了28.4 BLEU,比现有的最佳结果有所改进,包括乐团,由超过2 BLEU。在WMT 2014英法翻译任务中,我们的模型建立了一个新的单一模型,其最先进的BLEU得分为41.0在8个GPU上训练3.5天,这只是训练成本的一小部分文献中的最佳模型。
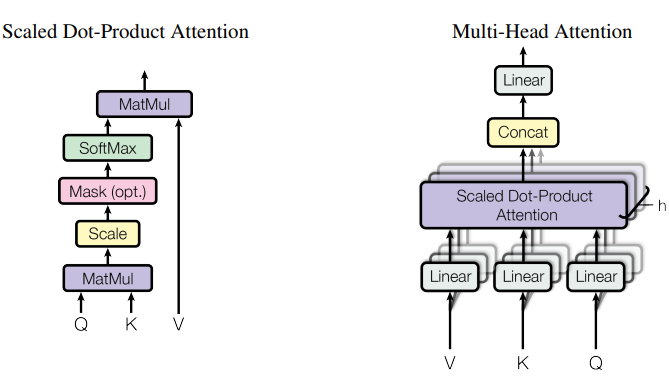
实际上,我们会同时计算一组查询的注意力函数,将这些查询打包到一个矩阵 Q 中。
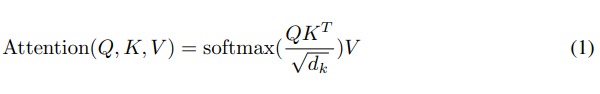

Transformer使用自注意力层的三种不同方法
